How to serve API for humans?

In today's digital landscape, serving APIs has become increasingly challenging. The task of exposing data and functionality to legitimate users has evolved into a complex battle against automated attacks, aggressive crawlers, and misguided AI training attempts.
The challenge isn't just technical—it's philosophical.
How do you distinguish between legitimate automation (which powers the modern web) and malicious bots that drain resources and compromise security?
How do you balance accessibility with protection, especially when dealing with rate limiting, bot detection, and content delivery networks like Cloudflare? This post explores the real-world challenges of maintaining APIs that serve humans while fighting with army of automated requests that seem determined to treat every endpoint as their personal data source.
Intro
As I enjoy working with multiple folks, one of my colleagues is running a company that collects a lot of data. Really cool data. The goal is to give everyone on the Internet a chance to see it or work with them. The problem on the other hand is that is not a real-time system, data are updated once a day. So hitting API every second is emm, pointless as you get exactly the same date 86400 times.
And it's a problem on my side, as it just uses a lot of resources, especially if we have multiple IPs that work in that way. So what's the scale of the challenge? For less than ~ 40K requests in 24 hours, mostly on Sunday.
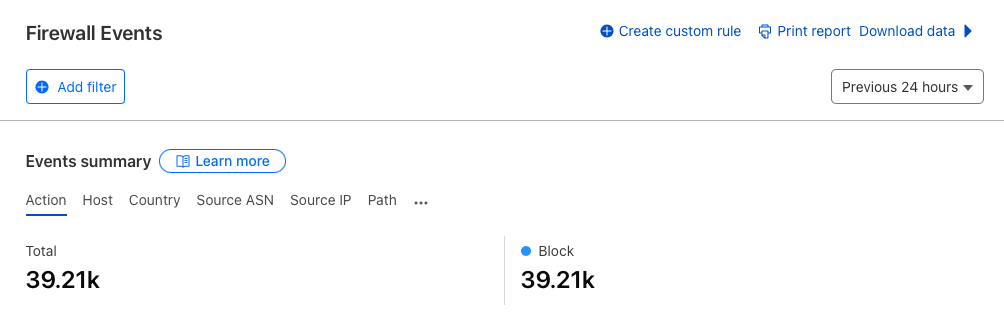 |
|---|
| 39.21k requests, where 39.21 were blocked |
Iteration 1
Ah, it's time to clarify, we're using Cloudflare at the front, and then API is hosted in different places, this particular one is using Azure App Services. (yep, I can into Azure as well). But that's not a point, I'm not a developer, I was contracted here to just do a security/network job.
My first idea was to observe data from the Events tab and try to understand the pattern. For me blocking a particular IP wasn't an option.
Why? This requires a bit of specific knowledge. As you may know, I'm living in Poland, and having a static IP it's not a default option. If you need it, you need to pay a bit more extra for the business plan in most cases. Based on that fact, and information that our My favorite client is from Poland as well (at least based on CloudFlares' data), blocking just IP doesn't have sense, as it will change after some time, and we will block random person or organization on the internet.
The first iteration was the usage of the classic rate limit. Also, note, that it's partly supported by Terrafrom modules, so our code was more or less:
1resource "cloudflare_ruleset" "rl_custom_response" {
2 zone_id = "<ZONE_ID>"
3 name = "Rate-limit bots"
4 description = ""
5 kind = "zone"
6 phase = "http_ratelimit"
7
8 rules {
9 ref = "rate_limit_example_com_status_404"
10 description = "Rate limit requests to www.example.com when exceeding the threshold of 404 responses on /status/"
11 expression = "http.host eq \"www.example.com\" and (http.request.uri.path matches \"^/status/\")"
12 action = "block"
13 action_parameters {
14 response {
15 status_code = 429
16 content = "{\"response\": \"API refresh data, one a day. Come back tommorow\"}"
17 content_type = "application/json"
18 }
19 }
20 ratelimit {
21 characteristics = ["ip.src", "cf.colo.id"]
22 period = 10
23 requests_per_period = 5
24 mitigation_timeout = 30
25 counting_expression = "(http.host eq \"www.example.com\") and (http.request.uri.path matches \"^/status/\") and (http.response.code eq 404)"
26 }
27 }
28}
There were no changes after that, we got a lot of blocked IPs, but they are still pinging the API. That was great evidence, that bots are used for home automation or some not very important system. Also, it introduces a problem, we have no idea how users use the data. After a while, we realized, that a lot of browser-based users were blocked. Probably due to the constant refreshing of some kinds of dashboards.
In the meantime, we changed the custom reposne, to Managed Challange.
Unfortunately, it doesn't solve the issue with user behaviors.
Iteration 2
At this point, we're sure, that the rate limit without knowledge about API usage could be a challenge. So we've been forced to find a different solution.
The next step was to block IPs to at least cut off, the most active autmated users. As it works, as expected, we have noticed a lot of requests classified by Cloudflare as Azure/AWS/etc. What it could mean? Probably some Machine learning processes. Again, blocking whole hyperscaler subnets is just pointless, we can't block the whole Internet, right?
Iteration 3
At this point after tracking an events dashboard, I realized that there is a simple way to block "not-browser" users. Check a user agent. After a short debug session, I was able to build the first user-agent-based block query. Which looks like that:
1(http.user_agent eq "") or
2(http.user_agent eq "got (https://github.com/sindresorhus/got)") or
3(http.user_agent eq "Embarcadero RESTClient/1.0") or
4(starts_with(http.user_agent, "python-requests"))
This very simple method allows me to drop all, non-human requests. So far so good, right?
Iteration 4
After a while and a few days of watching events, I realized that a few requests are made by AI crawlers.
 |
|---|
| AI crawlers hitting public APIs |
That's led to more philosophical questions. Should
we treat it as users who are seeking knowledge, and
GenerativeAI finds out our data is valuable. Or we should block it,
as it does not generate traffic to our blogs, or app, just use the
data without linking to it?
Also, it will probably include results and path in the newly trained
model, what will be the situation when path is updated, and
the model will redirect the user to the wrong source? Who will be responsible for it? Our company, or model owner?
To just avoid these questions, we will block it for now. If you
have a different option let me know!
Summary
This not-such-long article could be summarised in a few lines of text, and it is exactly what I will do.
To protect your API, no matter what tool you use, you need a few steps:
- Observe events and logs of your API
- Try to find a pattern
- Implement a rather, simple, not aggressive solution
- Keep observing, try to understand users, not developers
- Implement another rule, based on the results
- Keep integrating until, your resources are happy, as well as your clients, and wallet (if you're using the cloud)
That's for reading it, if you find it interesting, or you have different observation ping me on Mastodon or via email.